卡尔曼滤波在非线性系统下的应用
扩展卡尔曼滤波
主要思路:将递推公式用一阶泰勒展开近似,缺点也比较明显,某些情况下,局部线性化并不能很好的逼近真实值。
对于某系统模型有: 其中,$e_t$表示过程误差。
对于观测模型有: 其中,$\delta_t$是观测误差。
函数$g(\mathbb x_{t-1}, \mathbb u_t)和h(\mathbb x_t)$可以是非线性函数,所以需要先将这两个函数做泰勒展开,有:
其中,$G_t, H_t$分别表示预测模型和观测模型对状态的一阶导(雅克比矩阵)。
预测 更新
无迹卡尔曼滤波
主要思路:采样数值方法。因为系统比较复杂,直接采用蒙特卡罗方法,随机样本模拟,然后统计样本的均值和方差作为运动后的均值和方差。
关键问题:如何选取样本?
无迹变换(Unscented Transform)
核心思想:近似一种概率分布比近似任意一个非线性函数或非线性变换容易。
假设n维变量$\mathbb x$ 服从某均值为$\mathbb \mu$协方差为$P_x$的分布,变量经过某变换$\mathbb f$,得到$\mathbb y$,有$\mathbb y = \mathbb f(\mathbb x)$求$\mathbb y$的均值和分布。
UT变换算法如下:
-
根据$\mathbb \mu, P$采用一定的采样策略获得$sigma$点集${\chi_i}$。
$w_i^m,w_i^c$分别是均值和方差的权重。第一个点的均值权重和方差权重为: 剩下点的均值权重和方差权重为: $\alpha, \beta, \lambda$是输入的常量,也是需要调整的参数, 其中$k$影响着采样点到均值点的距离。
-
对$sigma$中的每个点分别做变换得到点集${\mathbb y_i}$
-
对点集$\mathbb y_i$,依据权重分别计算均值和方差,$\bar {\mathbb y}, P_y$,
UKF算法过程
预测
- 根据UT变换生成$sigma$点集$\Chi_{t-1}$
- 对点集$\Chi_{t-1}$中的每一个点分别执行$g(u_t, \chi_i)$
- 根据式(13)计算点集均值和方差。
更新
-
根据UT变换生成sigma点集$\Psi_{t}$
-
对点集$\Psi_t$中的每一个点执行观测变换函数$h(\psi_i)$,得到点集$\mathcal Z_t$
-
计算点集$\mathcal Z_t$的均值和协方差矩阵
-
计算x到z的变换矩阵
-
计算增益$K_t = P_t^{x, z} S_t$
-
更新均值和方差
应用
车辆在低速状况下可以用如下模型描述: 写成矩阵乘法的形式: $$ \mathbb x_{t +1} = \begin{pmatrix}
- \quad 0. \quad 0. \quad 0. \
- \quad 1. \quad 0. \quad 0. \
- \quad 0. \quad 1. \quad 0. \
- \quad 0. \quad 0. \quad 0.
\end{pmatrix} \mathbb x_t + \begin{pmatrix} dt \times cos(\theta_t) \quad 0
dt \times sin(\theta_t) \quad 0
0 \quad dt
1.0 \quad 0
\end {pmatrix} \mathbb u_t $$
这里简化了模型的处理,$\delta, a$是控制输入。车上携带了一个可以输出定位信息的传感器,要求能实时估计估计车辆的位姿。
完整代码可以参考extend_kalman_filter.py,这里先给出车辆仿真部分的代码
class Car:
def __init__(self, x = 0.0, y = 0.0, yaw=0.0, v = 0.0, L=1.0):
self.x = x
self.y = y
self.yaw = yaw
self.v = v
self.L = L
self.observe_variance = np.diag([0.4, 0.4]) ** 2
self.process_variance = np.diag([1.0, math.radians(10)]) ** 2
self.a = 1.0
self.sigma = 0.1
def _calc_input(self):
self.a = 1.0
self.sigma = 0.1
return self.a, self.sigma
def move(self, dt=0.01):
a, sigma = self._calc_input()
self.x = self.x + self.v * math.cos(self.yaw) * dt
self.y = self.y + self.v * math.sin(self.yaw) * dt
self.yaw = self.yaw + sigma * dt
self.v = a
def observe(self):
x = self.x + np.random.randn() * self.observe_variance[0, 0]
y = self.y + np.random.randn() * self.observe_variance[1, 1]
return x, y
def get_input(self):
a = self.a + np.random.randn() * self.process_variance[0, 0]
sigma = self.sigma + np.random.randn() * self.process_variance[1, 1]
return a, sigma
def state(self):
return self.x, self.y, self.yaw, self.v
扩展卡尔曼滤波
前面讨论过扩展卡尔曼滤波主要是对预测函数$g(\mathbb x_{t}, \mathbb u_t)$和观测函数$h(\mathbb x_{t})$做展开。
根据模型,求导有
具体实现代码
class PositionEstimator:
def __init__(self, initial_state, initial_P):
"""
:param initial_state:
"""
self.X = initial_state
self.P = initial_P
def jacob_F(self, x, u, DT=0.01):
"""
:param x:
:param u:
:return:
"""
yaw = x[2, 0]
v = u[0, 0]
j_f = np.matrix([
[1.0, 0.0, - DT * math.sin(yaw), DT*math.cos(yaw)],
[0.0, 1.0, DT * math.cos(yaw), DT*math.sin(yaw)],
[0.0, 0.0, 1.0, 0.0],
[0.0, 0.0, 0.0, 1.0]
])
return j_f
def prediction(self, u, Q, DT=0.01):
F = np.matrix('''
1. 0. 0. 0.;
0. 1. 0. 0.;
0. 0. 1. 0.;
0. 0. 0. 0.''')
B = np.matrix([[DT * math.cos(self.X[2, 0]), 0], [DT * math.sin(self.X[2, 0]), 0], [0.0, DT], [1.0, 0]])
X_prd = F * self.X + B * u
j_f = self.jacob_F(self.X, u, DT=DT)
self.P = j_f * self.P * j_f.T + Q
self.X = X_prd
return self.X, self.P
def jacob_H(self, x):
j_h = np.matrix([[1, 0, 0, 0], [0, 1, 0, 0]])
return j_h
def estimation(self, z, R):
j_h = self.jacob_H(self.X)
y = z - j_h * self.X
S = j_h * self.P * j_h.T + R
K = self.P * j_h.T * np.linalg.inv(S)
self.X = self.X + K * y
self.P = (np.eye(self.X.shape[0]) - K * j_h) * self.P
return self.X, self.P
def ekf_estimation(self, u, z, Q, R, DT=0.01):
self.prediction(u, Q, DT=DT)
self.estimation(z, R)
return self.X, self.P
无迹卡尔曼滤波
class UKFPoseEstimator(object):
def __init__(self, initial_state, initial_p, ALPHA, BETA, KAPPA):
self.X = initial_state
self.P = initial_p
self.wm, self.wc, self.gamma = self._setup(self.X.shape[0], ALPHA, BETA, KAPPA)
def _setup(self, n, ALPHA, BETA, KAPPA):
lamda = ALPHA ** 2 * (n + KAPPA) - n
wm = [lamda / (lamda + n)]
wc = [lamda / (lamda + n) + (1 - ALPHA ** 2 + BETA)]
for i in range(2 * n):
wm.append(1.0 / (2 * (n + lamda)))
wc.append(1.0 / (2 * (n + lamda)))
gamma = math.sqrt(n + lamda)
wm = np.matrix(wm)
wc = np.matrix(wc)
return wm, wc, gamma
def _generate_sigma_points(self, gamma):
sigma = self.X
P_sqrt = np.matrix(scipy.linalg.sqrtm(self.P))
n = self.X.shape[0]
for i in range(n):
sigma = np.hstack((sigma, self.X + gamma * P_sqrt[:, i]))
for i in range(n):
sigma = np.hstack((sigma, self.X - gamma * P_sqrt[:, i]))
return sigma
def _predict_motion(self, sigma, u):
for i in range(sigma.shape[1]):
sigma[:, i] = self._motion_model(sigma[:, i], u)
return sigma
def _motion_model(self, X, u, DT=0.1):
F = np.matrix('''
1. 0. 0. 0.;
0. 1. 0. 0.;
0. 0. 1. 0.;
0. 0. 0. 0.
''')
B = np.matrix([[DT * math.cos(X[2,0]), 0],
[DT * math.sin(X[2,0]), 0],
[0, DT],
[1, 0]])
X_prd = F * X + B * u
return X_prd
def _observation_model(self, X):
H = np.matrix('''
1. 0. 0. 0.;
0. 1. 0. 0.
''')
return H * X
def _calc_sigma_covariance(self, X, sigma, Q):
nSigma = sigma.shape[1]
d = sigma - X[0:sigma.shape[0], :]
P = Q
for i in range(nSigma):
P = P + self.wc[0, i] * d[:, i] * d[:, i].T
return P
def _calc_p_xz(self, sigma, x, z_sigma, zb):
nSigma = sigma.shape[1]
dx = np.matrix(sigma - x)
dz = np.matrix(z_sigma - zb[0:2, :])
P = np.matrix(np.zeros((dx.shape[0], dz.shape[0])))
for i in range(nSigma):
P = P + self.wc[0, i] * dx[:, i] * dz[:, i].T
return P
def predict(self, u, Q, DT=0.1):
sigma = self._generate_sigma_points(self.gamma)
for i in range(sigma.shape[1]):
sigma[:, i] = self._motion_model(sigma[:, i], u, DT=DT)
self.X = (self.wm * sigma.T).T
self.P = self._calc_sigma_covariance(self.X, sigma, Q)
return self.X, self.P
def estimation(self, z, R):
z_pred = self._observation_model(self.X)
y = z - z_pred
# calculate K
sigma = self._generate_sigma_points(self.gamma)
# mean
zb = (self.wm * sigma.T).T
# to observation points
for i in range(sigma.shape[1]):
sigma[0:2, i] = self._observation_model(sigma[:, i])
z_sigma = sigma[0:2, :]
st = self._calc_sigma_covariance(zb, z_sigma, R)
Pxz = self._calc_p_xz(sigma, self.X, z_sigma, zb)
K = Pxz * np.linalg.inv(st)
self.X = self.X + K * y
self.P = self.P - K * st * K.T
return self.X, self.P
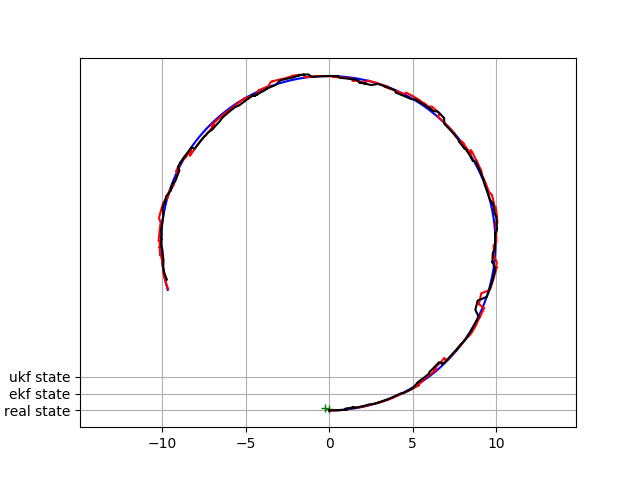
结果